Papeles del Psicólogo es una revista científico-profesional, cuyo objetivo es publicar revisiones, meta-análisis, soluciones, descubrimientos, guías, experiencias y métodos de utilidad para abordar problemas y cuestiones que surgen en la práctica profesional de cualquier área de la Psicología. Se ofrece también como foro para contrastar opiniones y fomentar el debate sobre enfoques o cuestiones que suscitan controversia.

Papeles del Psicólogo, 1990. Vol. (44-45).
N. SEISDEDOS
Aprovechando la disponibilidad de una muestra grande de candidatos españoles de casi todas las provincias españolas, el presente trabajo ofrece los resultados de muy diferentes análisis que unas veces parecen apoyar la idea de la elaboración de baremos específicos y otras propugnan la utilización de baremos generales. A lo largo de este proceso se hace una revisión de las supuestas diferencias inter-regiones españolas: mayor o menos dotación aptitudinal de unas provincias, regiones o Autonomías. La disyuntiva del tema (general/específico, nacional/local), no se proponen unas conclusiones concretas, pero se aboga por la construcción y utilización de baremos generales, puesto que permiten tanto la comparación entre los sujetos de un mismo grupo (candidatos en un proceso de selección) como el estudio de diferencias entre grupos de la población general PALABRAS CLAVE baremo, población, muestra, perfil, promedio y variabilidad.
Una persona sitúa las cosas, los lugares o a otras personas, en primer lugar, en relación con ella misma: «el ... está delante; la ... está al Este; ... es más alto». En segundo lugar, después de la fase anterior, el ámbito de referencia se abre más, pero todavía hay una relación con el entorno próximo al individuo. Al hablar de Aragón, en Madrid se dice que está al Este, y en Cataluña que está al Oeste; ¿está al Este o al Oeste? El problema reside en los puntos de referencia (porque los lugares están donde están, en una situación con sus coordenadas), y acudiendo a esos puntos se le da una situación relativa, en relación con otro.
Cuando, posteriormente, el ámbito de referencia se abre todavía más allá del mismo individuo, parece que los lugares tienen una situación más estable: en España, Salamanca está al Oeste (aunque los zamoranos nos insistan en que está al Sur).
Para terminar, con esa indefinición de la línea Oeste-Este (pero sólo dentro del planeta Tierra), se buscó una línea vertical imaginaria (meridiano de Greenwich) para situar referencialmente todos los puntos en una escala de medida de valor universal: Madrid está a unos 3º 45º al Oeste. A partir de este momento, todos podemos entendernos al dar la situación de un punto, utilizamos esa misma escala (minutos, grados y segundo) y esa misma línea de referencia (Greenwich).
En los procesos de selección también -se quiere situar a las personas en una escala de medida y en relación con unos puntos de referencia (baremo) más allá del mismo candidato y el mismo seleccionador. La amplitud de esa «referencia» ha sido el tema promotor de estas páginas.
Anteriormente, en otras ocasiones (principalmente a la hora de redactar los Manuales de varios tests), hemos abordado esta cuestión: la conveniencia de disponer de un solo baremo para la población general o de varias tablas normativas para subgrupos específicos de esa población general. Ambas posturas tienen sus defensores y argumentos.
Vamos a ejemplificarlo de la siguiente manera. Nos encontramos en un proceso de selección, dentro de nuestra empresa, en el que estamos buscando un buen candidato para el puesto de jefe de Almacén; hemos decidido que esta actividad exige la aptitud numérica y tenemos como candidatos al contable señor Tena y al vendedor señor Paso. Y estamos indecisos ante el tipo de baremo a aplicar:
a) Un baremo general de la variable aptitud numérica, al proponer un único rasero comparativo, facilita tanto la interpretación estadística de las diferencias entre varios grupos de la población como entre dos sujetos de igual o distinto grupo. Supongamos que tenemos los resultados de dos muestras y de los dos sujetos, tal como se indica en tabla 1.
TABLA 1. APLICACIÓN DE UN BAREMO GENERAL
|
Resultados |
Promedios |
Promedios |
Contables |
Vendedor |
|
Punt. directa Punt. típica |
45 72 |
30 47 |
39 63 |
34 54 |
Parece claro que, en aptitud numérica, los contables superan a los vendedores y el señor Tena alcanza una valoración mayor que la del señor Paso.
b) Los haremos locales o específicos sitúan comparativamente al sujeto en relación con un grupo de características semejantes a las suyas. Siguiendo con el ejemplo anterior, hemos elaborado para la aptitud numérica un baremo con los contables y otro con los vendedores. En este caso los promedios de ambos grupos obtienen una puntuación típica de 50 (se sitúan en el punto medio de la escala de las típicas). En este caso, los sujetos ya pueden ser comparadas con haremos ajustados a sus características; la tabla 2 presenta los resultados.
TABLA 2. APLICACIÓN DE UNOS BAREMOS ESPECÍFICOS
|
Resultados |
Baremo |
Baremo |
|
Punt. Directa Punt típicia |
39 37 |
34 58 |
El señor Tena con X-39 se sitúa por debajo de la media de su grupo (M-45 en la tabla l); tiene una aptitud numérica de tipo medio bajo. Sin embargo, el señor Paso con X-34 lo hace sobre el promedio del suyo (M-30 en la tabla l); tiene una aptitud numérica medio alta. Esas puntuaciones derivadas típicas no son las adecuadas para comparar al señor Tena, con el señor Paso si ambos son candidatos para un puesto de Jefe de Almacén.
Es probable que el seleccionador de este ejemplo le gustase tener también un baremo de Jefes de Almacén y en él, naturalmente el señor Tena obtendría una puntuación típica superior a la del señor Paso, la diferencia podría ir de 65 a 52 (si la muestra de jefes Almacén tuviese un promedio de M-35), o de 49 a 36 (si dicha muestra tuviese un promedio de M-40). Las cuantías absolutas citadas están en relación con el promedio de la muestra normativa (Jefes de Almacén) y la amplitud de la diferencia con la variabilidad de esta muestra normativa.
Ambos sujetos quedaron también claramente diferenciados cuando se utilizó el baremo general (tabla l); pero el seleccionador debe determinar a priori si la exigencia de la aptitud numérica por parte del puesto a cubrir (Jefe de Almacén) debe alcanzar una típica de 80 o es suficiente una de 60 o, incluso, de 50. En este último supuesto, y según la tabla 1, ambos candidatos superan esa exigencia, y habría que buscar otra variable o característica personal que sea decisorio en la selección.
Disponer de estadísticos básicos (media y desviación típica) de diferentes grupos de una población, así como analizar la posible significación estadística y psicológica de las diferencias, tienen valor suficiente en el campo de la psicología del trabajo y de las organizaciones: nos ayudan a comprender aptitudinal y psicológicamente los grupos.
Por otra parte, la existencia de unas creencias significativas no implican, por si mismas, la exigencia de unos baremos específicos. Podemos saber que los administrativos Banco del Banco CCC, como grupo, tienen una aptitud numérica superior a la de los administrativos de la Caja de Ahorros MMM; concluimos que la entidad CCC tiene un mejor potencial (en esa aptitud) que la MMM. Pero no por eso nos vemos obligados a elaborar unos baremos separados.
De forma parecida, podemos observar que una de las provincias, de las regiones o de Autonomías de nuestro país presente, frente a otras, unas diferencias estadísticamente significativas. ¿Indica esto que la labor de selección en esa provincia, región o Autonomía necesite unos baremos locales?
Muestras e instrumento
Hemos aprovechado la ocasión de un proceso de selección realizado en la misma fecha y con el mismo instrumento en casi todas las españolas para intentar un análisis de las posibles diferencias.
La muestra total está constituida por 18.367 casos y el instrumento de medida se ha a aplicado en 48 de las 52 entidades (incluyendo Ceuta y Melilla) provinciales españolas. Los grupos varían de N = 20 (Teruel) a N = 2.869 (Madrid), con una media de 383 casos (y en 8 la cuantía es inferior a 100).
El instrumento es una prueba de tipo «omnibus», con elementos aptitudinales (de razonamiento, de aptitud verbal y perceptiva), y, en mayor número, de conocimientos generales. El promedio nacional de los aciertos en la prueba supera sólo ligeramente el 50 por 100 de los elementos existentes, y la variabilidad de las puntuaciones, es bastante grande como para afirmar que el instrumento, en su conjunto, es discriminativo.
Al llegar este momento se nos plantea la disyuntiva indicada en la Introducción: un baremo nacional o haremos locales. El lector avezado en análisis de muestras nos propondría estudiar la posible existencia de diferencias intergrupos (sean provincias, regiones o entidades autonómicas). Además, la ocasión (con una muestra tan grande) parece que ni pintada para hacer unos «pinitos»- en esa línea. ¡Adelante!; hagámosle caso al lector, para su curiosidad y la nuestra.
Nos armamos de esa «paciencia de incansable investigador» y dividimos la muestra en las 48 entidades provinciales existentes, calculamos todos los estadísticos básicos y analizamos las posible diferencias inter-provinciales.
Análisis y resultados. Tenía razón el avezado lector, ¡había diferencias!. Para dar una idea de ello, ordenamos las 48 provincias de mayor o menor puntuación y calculamos sus alojamientos típicos (es decir, las puntuaciones «z» comparando cada media provincia con la media y desviación típica de toda la población). A continuación reproducimos en la tabla 3 las cuatro provincias superiores y las cuatro inferiores según su puntuación media en la prueba.
TABLA 3. PROVINCIAS DESTACADAS
|
Provincias interiores a la medida |
Provincias superiores a la medida |
|||||||
|
Tener. |
G.C. |
Badaj. |
Almer. |
Logr. |
Oren. |
Zarag |
Teruel |
|
|
N Z |
350 -0,51 |
277 -0,40 |
358 0,39 |
328 0,24 |
159 0,35 |
200 0,38 |
625 0,41 |
20 0,52 |
Todos esos alejamientos típicos son estadísticamente significativos a un elevado nivel de confianza. Los candidatos de las provincias del recuadro de la izquierda son claramente inferiores al promedio nacional y, naturalmente. Inferiores a los de las provincias de la derecha de la tabla 3. ¿Qué hacemos?, ¿un baremo para cada provincia?, o, tal vez, ¿sería preferible hacer tres baremos, uno para las cuatro provincias inferiores, otro para las cuatro superiores y un tercero para la población intermedia?
En la figura 1 hemos representado superpuestos los gráficos teóricos de los tres baremos. Hay un gran solape entre ellos, pero también hay zonas específicas de los grupos extremos. ¿Le gustarían así a ese lector avezado? Tenemos nuestras dudas, pero podríamos darle ese gusto y satisfacer sus deseos diferenciales.
Ver Figura 1.
Otro lector, avezado también en otros aspectos y partidario a favor de la división de España en entidades autonómicas, nos podría proponer el análisis de las submuestras autonómicas. Si hubiera diferencias justificables, se animaría a decirnos que le «gustaría» tener baremos locales.
La «paciencia del incansable investigadora se pone a su disposición; se toman los 18.367 sujetos y se clasifican por la entidad autonómica en la que fueron examinados (no nos atrevemos a decir «por la entidad autonómica a que pertenecen» porque, pese a los deseos y esfuerzos de algunos entusiasmados, sabemos de la heterogéneo composición de dichas entidades). Se calculan los estadísticos descriptivos y se hacen los correspondientes análisis de diferencias.
¡Tenía razón también nuestro segundo avezado lector! Existen diferencias que, como los «n» de las submuestras son ya bastante grandes, resultan pronto estadísticamente significativas. Hemos incluido Ceuta (n = 137, «z» = 0,12) y Melilla (n = 147, «z» = -0,01) en Andalucía, que sin ellas tendría una desviación de «z» = -0,12 en vez de la «z» = 0,11 que ahora tiene.
En la tabla 4 se reproducen las 17 entidades autonómicas indicando el número de provincias de las que teníamos información en nuestra población general y el «n» de la submuestra. Los alejamientos de la media total vienen expresados en puntuaciones «z» y puntuaciones S (una escala con media de 50 y desviación típica de 20, es decir, que entre los valores 30 y 70 se encuentra el 68 por 100 de los casos y entre los valores 1 y 99 está el 99,50 por 100). En su presentación hemos ordenado las autonomías de menor a mayor puntuación en la prueba.
TABLA 4. AUTONOMÍAS DE LA MEDIDA GENERAL
|
Autonomía |
Prov. |
N |
Z |
S |
|
Canarias |
2 |
627 |
-0,46 |
41 |
A la vista de los datos, las medias de todas las entidades se encuentran holgadamente dentro de la zona central (± 1 d. t.) de la muestra general. Sin embargo, dado el N de la muestra total y los n de las submuestras, muchas diferencias interentidades son estadísticamente significativas; en líneas generales, basta una diferencia de 0,13 unidades «z» o de 3 unidades S para que dicha diferencia resulte significativa al nivel de confianza del 1 por 100. Tal vez al lector le sea más ilustrativo examinar el contenido de la tabla 4 en la forma de un gráfico que destaque los alejamientos; lo hemos representado en la figura 2.
Ver Figura 2 y 3.
Por tanto, para darle gusto a nuestro lector interesado por este análisis diferencial inter-autonomías, habría que hacer haremos en casi todas, o bien reunir algunas que no se diferencian mucho entre sí. En este último caso, le podríamos preguntar a este lector si él cree conveniente «reunir», en el mismo grupo, por ejemplo, Madrid y Galicia, y ¿por que no?, también con el País Vasco que no se aleja significativamente de las dos anteriores. ¿Cuántos haremos cree él que deberíamos hacer para responder a la significación ¿estadística de las diferencias?
Quizá le ayude también aquí al lector el verlo de un modo gráfico; en la figura 3 se han proyectado los valores medios de cada entidad autonómica (en la abcisa, y con unas siglas o iniciales de su nombre: Cn = Canarias, Ex = Extremadura, An = Andalucía, etc.) en la escala de las puntuaciones S (en la ordenada); el perfil resultante de la población total es una línea más intensa.
A la vez, se han proyectado, para cada submuestra, los valores correspondientes a su media (M) + I d.t. empíricas, de modo que, recordemos, entre ellas se encuentre el 68 por 100 central de esa submuestra. El resultado final son dos bandas casi paralelas (con la inclinación o pendiente existente entre las entidades de menor a mayor puntuación en la prueba). Se podrá observar que muchos casos de Canarias situados en su zona central lo están también en la zona central de Aragón, aunque situados a distinta altura de esa zona central.
«Pero... ¡un momento! ... A mi me parece que ...». La interrupción a nuestra disertación es de otro atento lector que, aunque parecía seguir nuestra palabra con movimientos afirmativos de cabeza, estaba al hilo de sus divagaciones sobre lo que observaba. Dicho hilo iba por otros derroteros más geográficos que numéricos (tal vez por aquellas divagaciones Este-Oeste con que iniciamos nuestra introducción). Cuando todos le prestamos atención continuó diciendo: «Yo creo que esas diferencias tienen que ver con la latitud geográfica, porque las provincias o autonomías con mejor puntuación están más Norte que las de peor puntuación».
¡Vamos, ya tenemos aquí ese razonamiento que aparece en charlas de cafetería!, que si los pueblos del Norte son más ..., que si el calor del Sur, etc. Pero ¡habrá que atender a su observación!
Nos volvemos a armar con la citada paciencia de investigador, y siguiendo sus sugerencias recomponemos la tabla 3 incorporando a cada una de las ocho provincias (con mejor y con peor puntuación directa en la prueba) el dato de su latitud, es decir, los grados de distancia al Ecuador; tomamos los datos en grados y décimas de un atlas geográfico y calculamos la media de los dos grupos de cuatro provincias y ... ¡parece tener razón el obervador con aficiones geográficas! las cuatro mejores provincias tienen una latitud de 41.7º y las otras cuatro están claramente más al Sur, con una latitud media de 33,1º.
«¡Seamos serios!..., ¿por qué no intentamos una técnica más estadística que tenga en cuenta todos los datos y no sólo esas provincias extremas?». (Las palabras entrecomilladas ahora son del investigador, pues viendo que se tambalea todo lo que venía mostrando, intenta entretener a la concurrencia con esta salida).
Acudimos de nuevo a nuestro almacén de paciencia y también a nuestro formulario; proponemos calcular en toda la muestra (N = 18.367) la correlación de Pearson entre ambas variables, porque la latitud es una variable continua y la escala de puntuaciones en la prueba también puede considerarse un continuo por su amplitud y buena variabilidad. El sumiso auditorio parece aceptarlo.
A todos los sujetos de una provincia se le adjudica la latitud de la capital de dicha provincia (donde fueron examinados con la prueba). Si nuestra consulta no ha sido desacertada, en nuestro país tenemos latitudes que van desde los 28,1º de Gran Canarias hasta los 43,5º de Santander.
El resultado ¡para nuestro asombro!, es un índice r=0,57,
altamente significativo; parece indicar que a mayor latitud (mas al Norte) se
obtienen mejores resultados en la prueba. ¡... (boquiabiertos)...! obsérvese
por si mismo el lector la pendiente de crecimiento en el gráfico de la
figura 4; con excepción del pico que presenta la latitud de los 35º el
aumento es sistemático y casi constante.
Ver Figura 4.
«¡No nos apresuramos!...» (la ayuda viene de otro atento lector que, compasivo con nuestro apuro, intenta echarnos un capote), «en el continuo de la latitud de la geografía española hay una ruptura, los 8,4º que hay desde Cádiz a Gran Canaria». Mientras digerimos la sugerencia pensamos para nuestros adentros que, según la estadística que nos enseñaron, si reducimos la desviación típica de una de las variables, disminuirá el coeficiente de correlación, y tal vez desaparezca su significación.
Así pues, proponemos «eliminar» las Canarias de la muestra general y rehacer los cálculos con los 17.740 «godos» o peninsulares. Se cumple lo que dice la estadística, ¡pero no lo suficiente!, pues obtenemos un índice de r=0,39 que, además de ser estadísticamente significativo, nos señala que hay un 15,21 por 100 de variabilidad común entre la latitud geográfica y los resultados de la prueba cuyos resultados venimos analizando.
¿Qué le podríamos decir ahora a ese lector con aficiones plausible y lanzamos al auditorio la «patata caliente».
No obstante, todavía queremos «comprender» las diferencias que hemos observado anteriormente en las tablas y gráficos, porque seguimos interesados en el problema de los baremos ¿uno nacional o varios locales?
Así, pues, volvemos a intentar nuevos análisis para conocer mejor las diferencias observadas y encontrar razones para que una u otra alternativa de baremos. El lector recordaría que, al principio, hemos señalado que la prueba es de tipo «omnibus», es decir, está compuesta por elementos que miden diferentes variables. Como también hemos indicado que hay un mayor porcentaje de elementos de conocimiento frente a los de aptitudes psicológicas, decidimos recomponer la prueba de modo que queden equiponderadas las variables existentes.
Tomamos la decisión de introducir 10 elementos de cada variable (razonamiento, verbal, perceptiva y conocimientos), y repetir los análisis con una prueba de 40 elementos y 4 subpruebas. Elaboramos las plantillas de corrección de estas cuatro subpruebas y se las aplicamos a la muestra general; queremos conocer si las diferencias encontradas son sistemáticas en las cuatro variables y en algunas de las submuestras analizadas hasta el momento.
Para ello hemos tenido que realizar numerosos análisis y obtener muchas tablas, demasiadas para el lector que haya podido llegar hasta estas líneas. Por tanto, vamos a comentar los resultados y resumirlas numérica y gráficamente. Queremos ahorrarle el fárrago de los números.
Para conocer los índices de dificultad (ID o porcentaje de sujetos que acierten un determinado elemento), hemos realizado un análisis de los 40 elementos (en toda la muestra y en algunas de las submuestras), de las cuatro subpruebas citadas: Razonamiento, Veral, Perceptiva y de Conocimientos (de tipo cultura general).
Para agilizar los análisis nos hemos centrado en una muestra variada (de 14 provincias) y reducida (N=5.313, aproximadamente un tercio de la general), y hemos seguido manteniendo separadas las submuestras de aquellas entidades en las que hemos observado algunas diferencias o tienen una cuantía grande de casos: Canarias (N=616), Sevilla (N=616), Sevilla (N=1.149), Cataluña (N=1.006), Madrid (N=2.859) y Zaragoza (N=625).
En la tabla 5 se presentan los promedios de los ID de los 10 elementos de cada subprueba y submuestra, y a la derecha se han elaborado los perfiles resultantes de la figura 5.
TABLA 5. PROMEDIOS DE ID EN LAS SUBPRUEBAS
|
Subp. |
Var. 5.3.13 |
Zar. 625 |
Mad. 2.859 |
Cat. 1.006 |
Sev. 1.149 |
Can. 616 |
|
Raz. Ver. Per. Con. |
76,7 85,2 84,3 58,5 |
82,9 88,0 90,0 61,7 |
79,5 86,9 86,9 58,8 |
78,2 85,6 87,7 56,5 |
76,8 84,9 85,2 51,3 |
72,6 78,0 76,5 53,9 |
A la vista de estos resultados, el lector observará que las subpruebas de aptitudes (y en mayor media la perceptiva), han resultado bastante fáciles para las submuestras que en análisis anteriores tenían mejor puntuación en la muestra total (Zaragoza, por ejemplo). Los elementos más discriminatorios y de dificultad media han sido los de conocimientos (57,5 en la muestra variada).
Tanto en los datos numéricos como en el gráfico se observa que las diferencias interentidades provinciales o autonómicas se mantienen de forma muy similar en todas las subpruebas; a los sujetos de Zaragoza los elementos de las cuatro subpruebas les resultan más fáciles que a los demás grupos, y los de Canarias (reunidas Gran Canaria y Tenerife) encuentran más difíciles todos los 40 elementos. Madrid y Cataluña (ésta con sólo 3 provincias) se mantienen alrededor de la media general, y Sevilla se sitúa sistemáticamente por debajo, pero superan los resultados de Canarias. La única excepción parecen ser los elementos perceptivos, que no se comportan como los demás; obsérvese que Sevilla, entidad claramente por debajo en los anteriores análisis y ahora también en las otras tres subpruebas, supera a la media en estos elementos perceptivos.
No obstante, podemos decir que las cuatro subpruebas (tres de aptitudes y una de conocimientos, con 10 elementos cada una) son tan sensibles como la prueba total (con bastante más de 40 elementos) a las diferencias interprovinciales o interautonómicas. Por tanto, las diferencias encontradas no pueden ser achacables a factores de muestreo o composición de la prueba.
El esquema es muy semejante cuando se calculen las puntuaciones directas en las subpruebas. Como el ID (índice de dificultad) es un porcentaje, sobre 100, y cada subprueba tiene 10 elementos, los promedios presentados en la primera parte (izquierda) de la tabla 6 son la décima parte de los ID de la tabla 5; las pequeñas desviaciones pueden ser debidas a los redondos de los cálculos.
La prueba perceptiva vuelve a presentar la peculiaridad citada, como si en ella los pueblos del Sur (si hacemos caso a las elucubraciones geográficas presentadas en páginas anteriores) no tuvieran el mismo escollo que en las demás subpruebas.
En la mitad derecha de la tabla 6 (y en milésimas para ahorrarle espacio al impresor de estas páginas), hemos resumido los resultados de los análisis relacionales llevados a cabo con las cuatro subpruebas y las diferentes submuestras. Se incluyen las intercorrelaciones de Pearson indicadas en la cabecera de columna, es decir, R-V quiere indicar la relación entre la subprueba de Razonamiento y la Verbal, y P-C la relación entre la Perceptiva y la de Conocimientos.
Si nos atenemos a la primera fila de índices (obtenida en una submuestra de más de cinco mil casos, de mayor variabilidad que el resto de las submuestras), aunque todos ellos son estadísticamente significativos a un elevado nivel de confianza, las mayores relaciones se encuentran entre las aptitudes y las menores entre éstas y los conocimientos. La variable que más influye en las demás es el razonamiento, la que probablemente tenga mayor componente del factor general de la inteligencia. Obsérvese también que los índices parecen aumentar al disminuir la dotación de loa sujetos, es decir, son generalmente mayores en Canarias que en Zaragoza. Ante este dato podríamos apuntar la siguiente hipótesis; cuando la dotación es menor las variables están más interrelacionadas porque para resolver los mismos ejercicios los sujetos acuden a toda su dotación o a niveles superiores de la estructura de la inteligencia; dicho con otras palabras y con un enfoque más evolutivo, cuando la dotación es mayor las variables son más independientes.
Sin embargo, aunque como estudiosos nos pueda satisfacer el haber constatado este hecho, como investigador nos vemos obligados a indagar más a fondo en los datos para intentar «falsear» la hipótesis apuntada en el párrafo anterior.
Por tanto, introducimos de nuevo nuestra «lupa» en los resultados de los análisis con las subpruebas y las submuestras, y creemos haber encontrado una plausible justificación de las diferencias en las interrelaciones.
La estadística que aprendimos nos señala que, en un estudio de relaciones, al aumentar la variabilidad crece también el coeficiente de correlación, es decir, que para interpretar un coeficiente hay que atender a la desviación típica, pues si ésta es pequeña el resultado es más significativo. Por tanto, en nuestra búsqueda de causas de la mayor interrelación en las submuestras con menor puntuación en las subpruebas, extraemos todas las desviaciones típicas para una atenta observación de las mismas.
Dichas desviaciones típicas se presentan en la tabla 7, y en la parte derecha se ilustran con un gráfico. Como las cuatro subpruebas tienen igual longitud (10 elementos), los valores absolutos son intercomparables; la subprueba menos variable es la Verdad y la más heterogénea en sus resultados la Perceptiva. En cuanto a submuestras (que es lo que veníamos indagando), la de menor variabilidad es Zaragoza y la de mayor en Canarias.
TABLA 7. VARIABILIDAD (d.t.) EN SUBPRUEBAS Y SUBMUESTRAS
|
Sum. |
Subp. Raz |
Subp. Ver |
Subp. Per |
Subp. Con |
|
Var. Zar. Mad. Cat. Sev. Can. |
1,59 1,42 1,53 1,56 1,57 1,82 |
1,34 1,17 1,28 1,32 1,27 1,53 |
2,38 1,93 2,16 2,14 2,42 2,93 |
1,92 1,76 1,85 1,92 1,88 1,92 |
Ver Figura 6 y Figura 7.
¡He aquí, probablemente, una plausible razón de la menor (Zaragoza) y mayor (Canarias) interrelación entre las variables! En Canarias (línea de puntos en el gráfico) los sujetos se extienden más que los de Zaragoza (línea continua inferior en el gráfico) en relación a su media; tal vez en Canarias haya casos que alcancen tan buena puntuación como la de Zaragoza (aunque su proporción sea menor), pero, también es muy probable, a la vez, que en la haya una mayor proporción de casos con puntuaciones inferiores.
Creemos que éste es un punto de interesante reflexión para decidir sobre la utilización de un baremo general o varios locales. Hemos calculado la puntuación suma de las cuatro subpruebas y construido las distribuciones empíricas de frecuencias de la submuestra más variada y de esas dos entidades extremas, Zaragoza y Canarias. La figura 7 presenta los gráficos resultantes. Son distribuciones asimétricas negativas, y su mayor capacidad discriminativa está en el polo bajo de la variable (debido a la facilidad de sus elementos); desde el punto de vista de un proceso selectivo, demasiados sujetos alcanzan la parte final de las pruebas. Por tanto, a la hora de examinar la figura 7 conviene recordar que en dicho proceso selectivo es el polo alto de la variable el que decide la elección de los mejores candidatos.
Como todavía estamos dudando sobre un baremo general (sobre la muestra variada) o sobre las entidades que presentan las mayores diferencias, vamos a elaborar en centiles (aprovechando las distribuciones y gráficos de la figura 7) los tres baremos, el de la submuestra variada, de características muy similares a la población general, y los de las dos submuestras más extremas-, en el cuerpo de la tabla 8 (a continuación de la figura 7), están las puntuaciones directivas y en cabecera de columna los centiles correspondientes.
Vamos a suponer que en el proceso selectivo, como tenemos superabundancia de candidatos, se decide considerar únicamente los candidatos que tengan una puntuación centil superior al 90, porque con ello se tienen suficientes candidatos. Si se aceptase esta solución, y con esta prueba de 40 elementos, se tendrían los siguientes resultados:
a) aplicado al baremo general (el de la muestra variada) el punto crítico es una X=:37 y:
- hay 64 casos en Zaragoza con 37 o más puntos,
- hay 20 en Canarias que cumplen esa condición.
b) aplicados los baremos específicos:
- En Zaragoza el punto crítico es 37, como en el baremo general; se dispone de 64 casos.
- En Sevilla el punto crítico es 35, y nos permite disponer de 37 sujetos que cumplen esa condición.
La diferencia cuando se tienen baremos específicos es que en Canarias se puede afinar mejor el proceso selectivo y disponemos de más candidatos que con el uso del baremo general. En términos absolutos la diferencia son 2 puntos de puntuación directa. ¿Son suficientes en una prueba como ésta 2 puntos directos para pensar en diferencias significativas?Estos nos recuerda que toda puntuación directa tiene un intervalo confidencial cuando la prueba no es perfectamente fiable. Para conocer este intervalo necesitamos el coeficiente de fiabilidad. Así que, ¡volvemos de nuevo a los análisis! ¡Esto no parece terminar nunca!
Vamos a obtener uno de los coeficiente de fiabilidad que nos permite la aplicación de una prueba en una sola ocasión, el que aplica el procedimiento de las dos mitades. Entre los 40 elementos, separamos los 20 elementos pares de los 20 elementos impares, calculamos las puntuaciones en estas, dos partes, obtenemos el índice correlación de Pearson entre ellas y corregimos el resultado con la fórmula de Spearman-Brown.
Hemos aplicado este procedimiento a distintas submuestras (de provincias y de autonomías), y hemos encontrado coeficientes de fiabilidad que varían desde 0,733 hasta 0,828; para dar algunos ejemplos específicos, el coeficiente ha sido de 0,783 en Sevilla, 0,743 en Zaragoza, 0,811 en Canarias, 0,752 en Madrid, 0,810 en Cataluña, etc. Esta fiabilidad no es elevada para un test de aptitudes; el procedimiento de las dos mitades no es el ideal y, probablemente haya descendido por la poca dificultad general del instrumento.
Antes de conocer el intervalo de confianza de una puntuación directa cualquiera, decidimos tomar como más representativo el coeficiente obtenido en la muestra variada (N= 5.313), con un valor de 0,783 y una variabilidad de 5,01 en los 40 elementos. Obtenido el error típico de medida y al nivel de confianza del 5 por 100 (menos exigente que el del 1 por 100), encontramos que toda puntuación directa puede venir afectado por un error de ± 4,57 unidades directas.
Aplicado este intervalo de confianza a las 2 unidades directas que señalábamos unos párrafos más arriba como principal diferencia, concluimos que aplicar un baremo general no parece distinto de aplicar un baremo específico o, dicho con otras palabras, tanto da el baremo específico como el general.
Después de tanto análisis hemos llegado a esta pobre conclusión. ¿No le parece esto un poco descorazonador al lector? Probablemente la conclusión no es tan pobre por que en ese camino, entre curva y curva, hemos cosechado algunos conocimientos que nos ayudarán en la interpretación cuando utilicemos un baremo general o específico.
Nuestras preferencias personales se inclinan por el baremo general, lo encontramos más útil, porque tiene las ventajas indicadas en la introducción (utilizando el mismo rasero, se pueden comparar tanto promedios de grupos como valores concretos de sujetos).
Lo ideal sería, además, que la muestra utilizada fuera representativa de la población. La muestra general que hemos utilizado en nuestro trabajo (N = 18.367 adultos jóvenes españoles) no ha tenido nunca la pretensión de representatividad. Es verdad que procede de casi todas las provincias españolas, pero la reunión de la misma no fue hecha intencionalmente buscando esa representatividad. Es general pero «incidental». Queremos señalar aquí esto por si alguien toma demasiado en serio nuestros «jocosos devaneos» de tipo estadístico y psicológico.
Es muy difícil y costosa la representatividad; lo hemos constatado al intentarlo de modo serio en la adaptación y tipificación de alguna de las pruebas del fondo de distribución de TEA Ediciones. En otras ocasiones, sin intentar esa representatividad y reuniendo muestras incidentales, hemos constatado también el valor de los baremos generales; ahora nos estamos refiriendo al Cuestionario de personalidad 16 PF en sus diversas formas; cuando alcanzamos una muestra de unos 400 casos hicimos una primera tipificación para ofrecer baremos generales a los usuarios de los instrumentos; posteriormente, hemos alcanzado el millar de casos y, para nuestra sorpresa los estadísticos se mantienen muy igualmente constantes (con pequeñas diferencias de centésimas o, a lo sumo, una o dos décimas de puntuación directa).
En estos casos (y sobre todo en la medida de rasgos de personalidad), cuando alguien nos ha propuesto construir un baremo específico (sobre un determinado grupo profesional, por ejemplo, vendedores), hemos aconsejado como más útil el elaborar el perfil específico de ese grupo, para conocer sus desviaciones características y seguir utilizando el baremo general. Cuando se utilice la prueba de personalidad en procesos de selección de vendedores, el profesional ya sabe que en este grupo los profesionales tienden a elevar la escala «X» y a bajar la escala «Y»; por tanto, una vez consultado el baremo general, interpreta los resultados concretos de los candidatos teniendo «in mente» esas crestas y valles del perfil de los vendedores.
Si este compañero nuestro utiliza baremos específicos (de vendedores, según el ejemplo), puede darse el caso de que le oigamos decir sobre un candidato: «Es una persona de extraversión media (tiene un centil 50 en el baremo de vendedores), pero ya se sabe que lo vendedores presentan una elevación en ese rasgo; es decir, que probablemente sea una persona de extraversión por encima del promedio». Si hubiera utilizado un baremo general, nos hubiera dicho: «Es una persona de extraversión medio alta, pero esto es lo normal entre los vendedores». ¿Cuál de estas dos posturas prefiere el lector de estas páginas?
Material adicional / Suplementary material
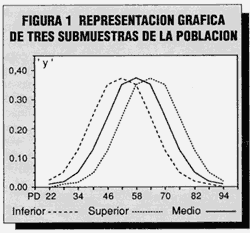
Figura 1. Representación Gráfica de tres submuestras de la población.
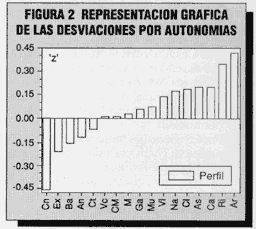
Figura 2. Representación Gráfica de las desviaciones por Autonomias.
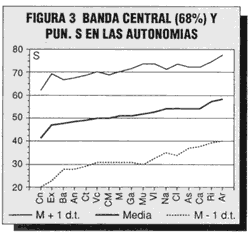
Figura 3. Banda Central y Pun. S en las Autonomias.
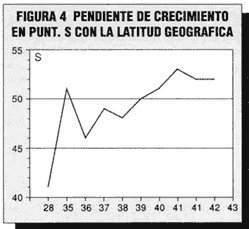
Figura 4. Pendiente de crecimiento en Punt. S con la latitud geográfica.
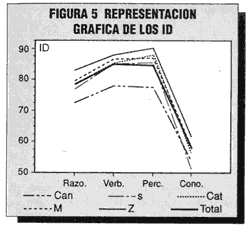
Figura 5. Representación gráfica de los ID.
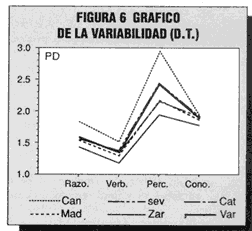
Figura 6. Gráfico de la variabilidad.
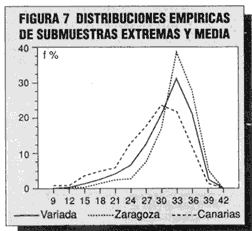
Figura 7. Distribuciones empíricas de submuestras extremas y media.